Solucionando la Penalización de Recarga en LibreQoS
• Herbert WolversonLibreQoS proporciona regulación de calidad de experiencia (QoE) y análisis para los usuarios, pero ha tenido un problema importante durante mucho tiempo. Desde la versión 1.4 de LibreQoS (lanzada en noviembre de 2023), recargar usuarios y el árbol de modelado podía detener el “pipeline” de procesamiento, causando ráfagas de pérdida de paquetes. Uno de mis colegas incluso lo llamó “olas aleatorias de desastre” — un repentino brote de problemas en toda la red.
Hemos estado trabajando en mejorar esto durante aproximadamente dos años. No creíamos que pudiera solucionarse completamente, ¡pero ahora tenemos problemas para reproducir el comportamiento!
En este largo artículo, voy a explicar el problema y el proceso de varios años para solucionarlo.
Mapas eBPF y Bloqueos
LibreQoS (a través del sistema lqos_sys) hace todo lo posible para evitar bloqueos en la ruta crítica de paquetes durante la operación normal. En la versión 1.4, cuando llegaba un paquete:
- “Analizamos” el paquete — leemos los encabezados VLAN/PPPoE/etc. hasta encontrar el “payload” IP. Luego determinamos direcciones de origen y destino, protocolo (TCP/UDP/ICMP) y puertos (para TCP/UDP) o tipo/código ICMP.
- Las direcciones IP se normalizan a un formato compatible con IPv6.
- Realizamos una búsqueda LPM (Longest Prefix Match) en el mapa
xdp-cpumappara identificar a qué circuito pertenece la dirección IP. - Redirigimos mediante
cpumapa la CPU adecuada (permitiendo quemqyhtbutilicen todos los núcleos del servidor). - Se ejecuta un segundo programa eBPF de clasificación
tc, que asigna el paquete a la fila correcta.
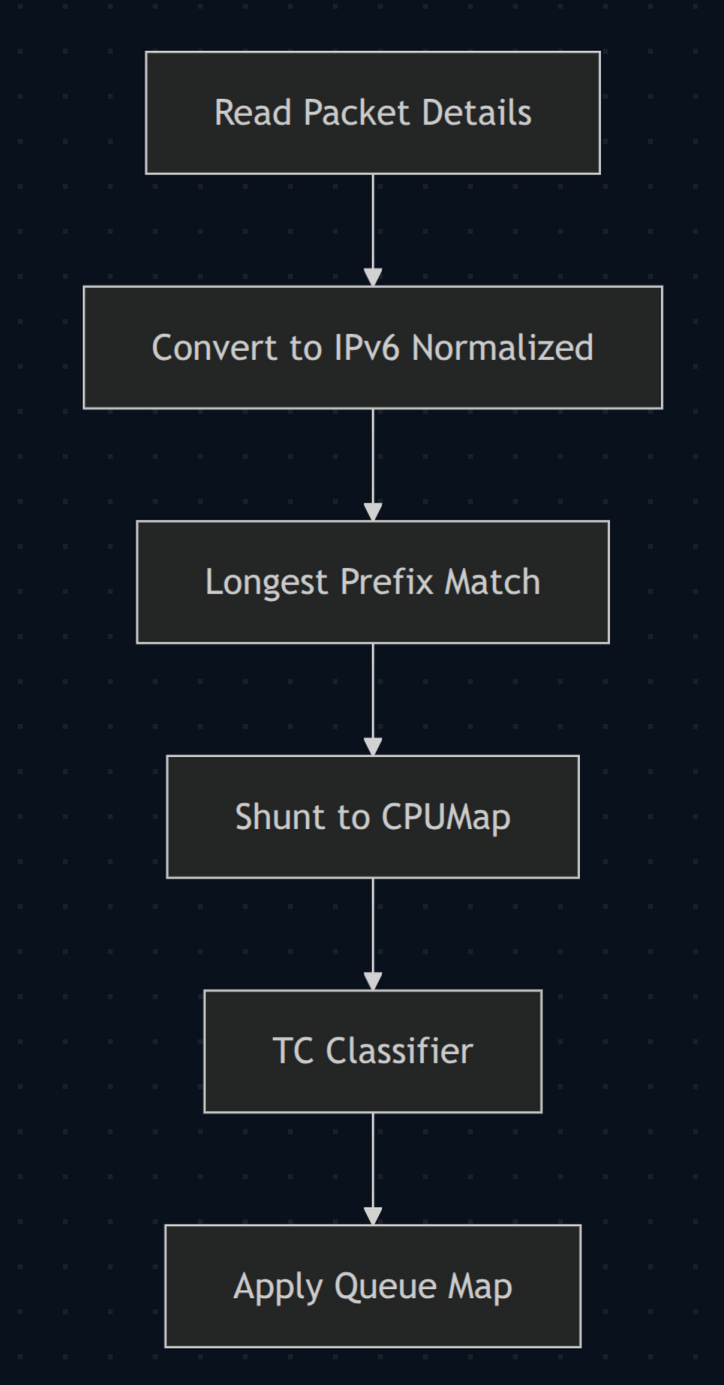
La recarga implicaba actualizar el mapa xdp-cpumap desde espacio de usuario. Estas actualizaciones requieren sincronización de escritura dentro del kernel y, bajo carga alta, esa contención podía volverse muy notable. Los programas XDP/TC tienen poco presupuesto por paquete; al acercarse al límite, incluso pequeñas pausas podían provocar pérdida de paquetes.
Cabe destacar que la sincronización basada en RCU de Linux es impresionante — este no es un reclamo contra Linux. Simplemente era un mal patrón de actualización de nuestra parte.
Introduciendo Iteradores eBPF
En la versión 1.4 nos dimos cuenta de que hacíamos algo incorrecto. Bloqueábamos todo el mapa xdp-cpumap, eliminando elementos uno por uno y volviéndolos a agregar en cada recarga. Cambiamos a un sistema de “eliminación en bloque” y vimos mejoras inmediatas.
También adoptamos la API de iteradores BPF, y recorrer los datos se volvió mucho más eficiente. Los ISPs pequeños rara vez veían el problema, pero los grandes seguían teniendo dificultades.
Añadiendo Sistemas de Análisis
A medida que LibreQoS crecía, Dave y yo adoptamos una filosofía: “todo esta regulación de tráfico es excelente, pero si no lo medimos — no podemos mejorarlo”. Como resultado, el uso de eBPF creció. Comenzamos a rastrear RTT de TCP, asignar tráfico a hosts en otro mapa eBPF, agregar captura de paquetes y monitorear el algoritmo CAKE.
Fue increíble y uno de los desarrollos más divertidos en los que he trabajado.
Desafortunadamente, también tuvo un costo: eBPF es difícil de desarrollar.
- El verificador exige demostrar que cada acceso a memoria es válido y cada bucle es finito.
- La pila es muy pequeña (cientos de bytes).
- La asignación de memoria es limitada; la mayor parte del estado vive en mapas eBPF.
Estas restricciones son razonables, pero también agravan el problema de bloqueos — ya que ahora el programa realiza más trabajo por paquete, haciendo que cualquier contención durante recargas sea más crítica.
Así que mejoramos LibreQoS — y empeoramos el problema de bloqueos.
Flujos
Con la versión 1.5, decidimos rastrear “flujos”. Es decir, datos entre dos puntos en el Internet. Es sencillo conceptualmente: usamos el 5-tuple (IP de origen, IP de destino, protocolo, puerto de origen, puerto de destino) y acumulamos datos. El análisis es oro puro, porque ahora puedes ver qué ASNs no están funcionando correctamente (y corregir el enrutamiento) y también puedes ver qué está fallando para los usuarios (puedes observarlos ejecutar una prueba de velocidad casi en tiempo real).
¡Y claro — esto empeoró aún más el problema de bloqueos!
Ahoara el “Pipeline” por paquete:
- Analizar paquete.
- Búsqueda LPM.
- Calcular hash de flujo.
- Actualizar contadores por host (estos son por CPU).
- Actualizar contadores por flujo.
- Registrar RTT y retransmisiones TCP.
- Enviar a
tc. - Repetir analisis.
- Repetir busqueda LPM.
- Asignar a la fila correcta
tc.
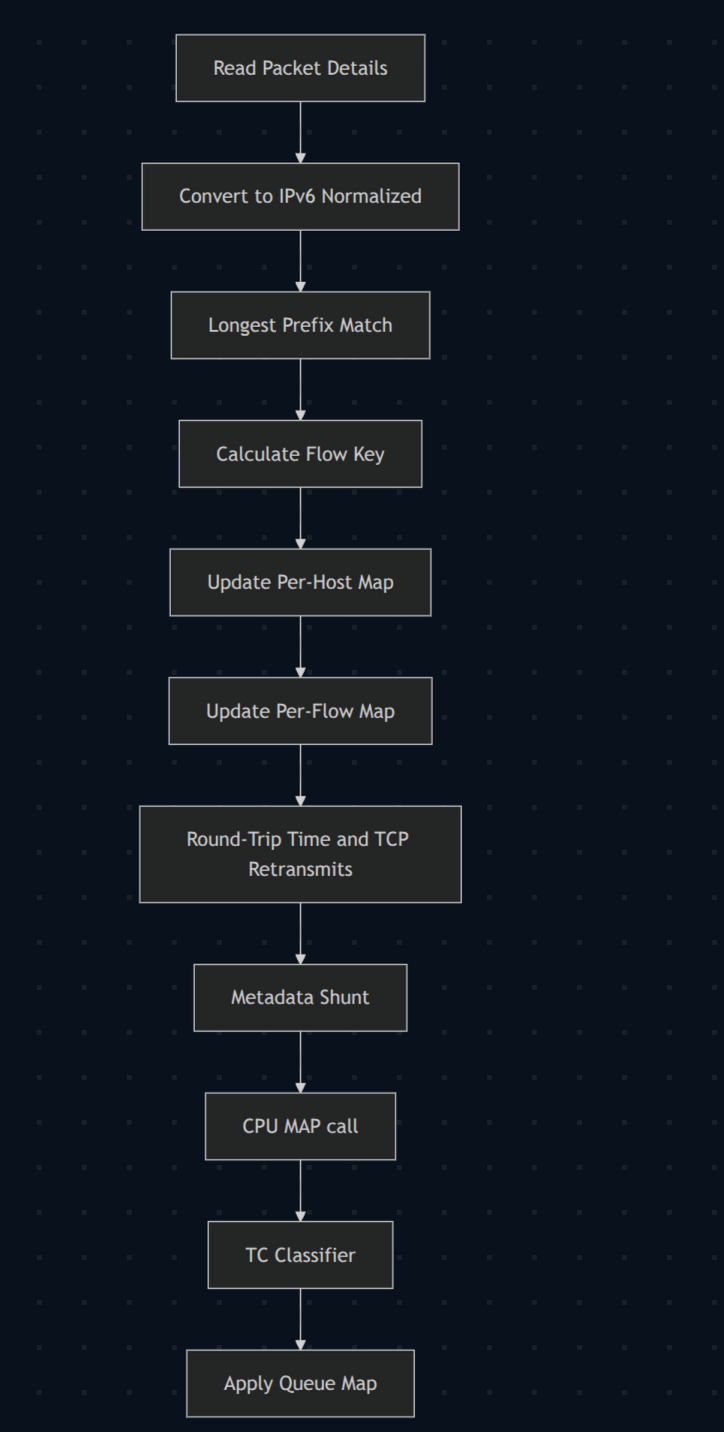
Eso es realmente bueno y potente. Estábamos alcanzando más de 40 Gbps en algunos equipos. ¡También es bastante pesado!
Entra el Hot Cache
El análisis de rendimiento mostró que la búsqueda LPM en xdp-cpumap era una fuente significativa de lentitud en la ruta por paquete. Así que añadimos un segundo mapa: el “hot cache”. Es un cache bastante bueno; soporta tanto resultados positivos (“esta IP corresponde a ese circuito”) como negativos (“esta IP no existe, deja de buscar”) en un mapa hash rápido.
Para cada paquete, primero consultábamos el hot cache y solo realizábamos una búsqueda LPM si el cache fallaba. Boom: una mejora instantánea del 10–20% en el “pipeline” de procesamiento de paquetes de LibreQoS. Celebramos mucho.
Y el bloqueo durante la recarga en realidad fue peor, porque ahora también teníamos que limpiar el hot cache. Incluso con funciones en bloque, resultó ser una operación más lenta.
Metadata
El sistema eBPF de Linux añadió “metadata” como funcionalidad general, así como la capacidad de transportarla entre XDP y tc. Esto te da un pequeño espacio “antes” del paquete que puedes usar para pasar datos entre un programa XDP y un clasificador tc. El verificador es estricto aquí: si no mantienes los punteros consistentes, pueden pasar cosas terribles. Justo; podemos vivir con eso.
Así que implementamos el “metadata shunt”. Cuando llega un paquete, se consulta con el hot cache/LPM y el resultado se escribe en metadata para la siguiente etapa. Esto elimina completamente la necesidad de una segunda búsqueda en el mapa. ¡Otro pequeño aumento en el rendimiento! Pero una vez más, el problema de recarga no cambió.
Función Bakery
Ya hemos hablado de la función Bakery antes. La versión corta es que nos enfocamos en reducir la cantidad de cambios que realizábamos. Fue un proceso de varias etapas que eventualmente:
- Eliminó la necesidad de limpiar completamente el estado de
xdp-cpumapy reconstruirlo desde cero en el 90% de los casos de recarga. - Permitió que algunos cambios (adición de circuitos y cambios de velocidad) ocurrieran sin una recarga completa.
Comenzamos a ver mejoras significativas en el proceso de recarga, pero aún no estábamos ahí. Los usuarios que seguían un modelo de “reescribimos el estado de la red regularmente” todavía veían problemas frecuentes. Para usuarios de UISP, Splynx u otras integraciones que aplican cambios en lotes, las mejoras fueron notables — pero la pausa no desapareció.
Reorganizando Cómo Clasificamos
Si observas los diagramas anteriores, estamos haciendo mucho trabajo por paquete. La parte “divertida” es que todo es trabajo bueno y necesario. No hay pasos que realmente podamos omitir.
Y entonces me di cuenta: ¡podíamos hacer los mismos pasos en un orden diferente! Así que reorganicé los mapas eBPF. El mapa xdp-cpumap cambió para almacenar directamente circuit_hash y device_hash (para ayudar a la interfaz). El mapa de flujos se amplió para incluir la CPU de destino y la clase tc.
Luego refactorizamos todo el “pipeline” de paquetes eBPF:
- Se analiza el paquete.
- Se calcula la clave de flujo (hash de IP de origen/IP de destino/protocolo/puerto de origen/puerto de destino).
- Se realiza una búsqueda de flujo.
- Si el flujo no existe: se realiza la búsqueda en hot cache + LPM y se llena el flujo.
- Si el flujo existe: se omite completamente la búsqueda en hot cache + LPM.
- Se realiza el mismo análisis.
- Metadata shunt hacia
tc-classify. - Asignación mediante
cpumap. - Asignación a la fila correcta.
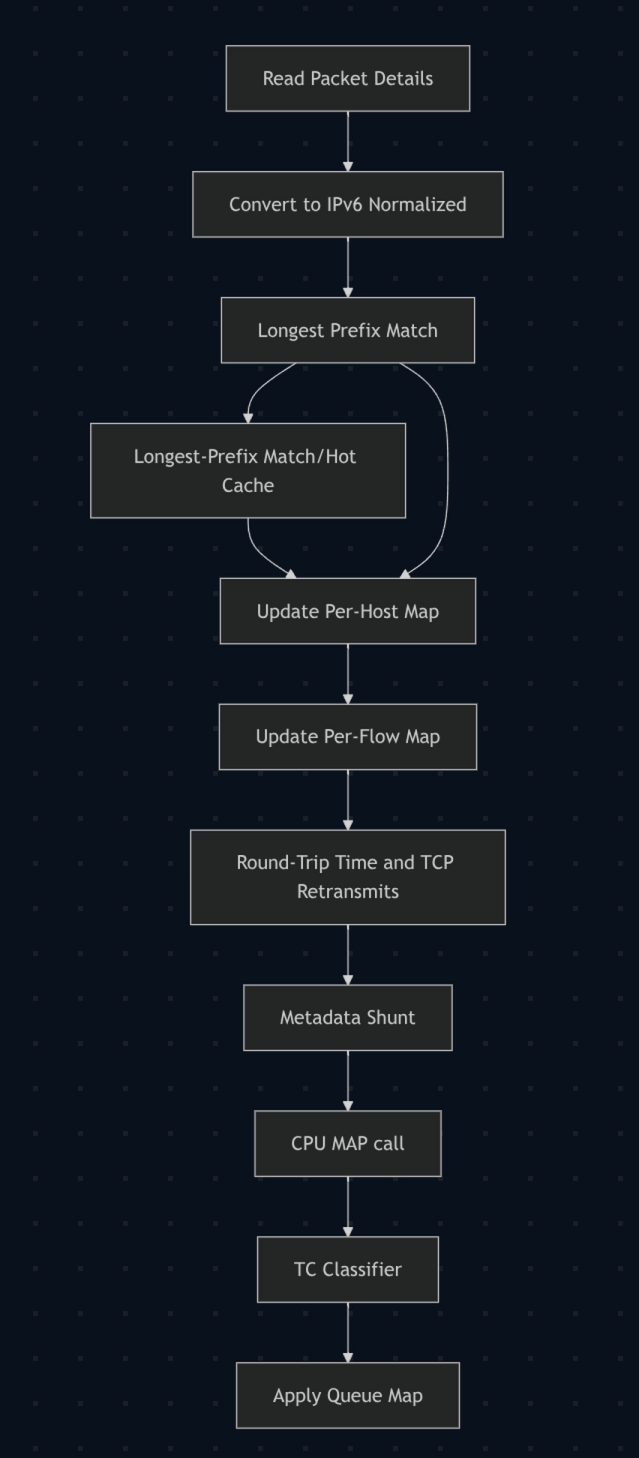
Esto es una GRAN mejora en términos de rendimiento, porque la mayoría de los flujos tienen más de un paquete. De hecho, la gran mayoría tiene al menos 10 paquetes, y algunos llegan a miles. Así que, promediado en todo el sistema, estamos realizando un orden de magnitud de menos iteraciones.
Y lo mejor de todo: los mapas que requieren bloqueo se consultan mucho menos frecuente. Fue una mejora inmediata de rendimiento e hizo que la pausa de “olas de desastre” fuera mucho más difícil de provocar.
Podrías pensar que es momento de celebrar y darlo por terminado. Pero no — ¡encontramos otro truco!

Epochs
En este contexto, un “epoch” es básicamente un contador de generación — un número que representa “qué versión de la realidad” pertenece un dato en cache.
Estaba leyendo un artículo sobre el funcionamiento interno de recolectores de basura de memoria (necesitaba ayuda para dormir), y encontré una descripción de cómo usar epochs para evitar actualizaciones con muchos bloqueos. Asignas un epoch a los datos, incrementas el epoch actual cuando cambia la realidad y tratas los epochs antiguos como obsoletos.
Y me di cuenta: podíamos hacer esto para el hot cache y los datos LPM. Así que ambos fueron rediseñados, reemplazando cada ciclo de limpieza/sobrescritura con un incremento de epoch.
Cada entrada lleva el epoch bajo el cual fue creada, y las búsquedas tratan un epoch antiguo como un fallo (por lo que se actualiza naturalmente). Las entradas antiguas permanecen, pero se ignoran y se reemplazan gradualmente con tráfico real (y, en mapas LRU, se eliminan cuando el mapa se llena). Esto resultó en código complejo y depuración interesante, pero en resumen: no más tormentas de bloqueo durante recargas. Hemos intentado recrear el problema y el sistema simplemente sigue funcionando.

Conclusión
Al escribir esto, me hizo recordar cuánto extraño trabajar con Dave en temas de bajo nivel. Te extraño, amigo. Descansa en paz.
De cara al futuro, esto abre puertas emocionantes. Podemos cambiar la estructura con muy poca penalización, lo que nos permite ofrecer funciones muy solicitadas. Aún no están disponibles, pero vienen en camino:
- Llamadas API para cambios en circuitos en tiempo real.
- Ajustes dinámicos de la red por razones de rendimiento.
- Posibilidad de recibir paquetes de contabilidad RADIUS para permitir la creación dinámica de colas en hotspots y sistemas en vivo.
¡Tiempos emocionantes! Gracias por acompañarme en esta gran actualización. Es contenido interesante, aunque bastante técnico — espero que sigas despierto.
Acrónimos
eBPF- Filtro de Paquetes Berkeley extendido. Pequeños programas que pueden ejecutarse en el kernel de Linux.QoE- Calidad de Experiencia.XDP- eXpress Data Path. Un “hook” de procesamiento de paquetes de alto rendimiento que se ejecuta muy temprano en la pila de red de Linux.RCU- Read-Copy-Update. Mecanismo de sincronización de Linux usado comúnmente en estructuras con muchas lecturas.RTT- Tiempo de ida y vuelta.ASN- Número de Sistema Autónomo.RADIUS- Remote Authentication Dial-In User Service.tc- Control de Tráfico de Linux. La parte del kernel de Linux que se encarga del control de tráfico.CAKE- Common Applications Kept Enhanced. Unqdiscde Linux usado para manejo de filas y regulación de tráfico.htb- Hierarchical Token Bucket. Funcionalidad del kernel de Linux para definir árboles de velocidad.mq- Multi Queue. Funcionalidad del kernel de Linux para usar múltiples CPUs.LPM- Longest Prefix Match. Dada una IP (por ejemplo192.168.1.5), devuelve el prefijo más específico (por ejemplo192.168.1.5/32vence a192.168.1.0/24).