Fixing the Reload Penalty in LibreQoS
• Herbert WolversonLibreQoS provides quality-of-experience (QoE) shaping and analysis for users, but it has had a major pain point for a long time. Since LibreQoS version 1.4 (released in November 2023), reloading users and the shaping tree could stall the processing pipeline, leading to bursts of packet loss. One of my colleagues even called it “random waves of suck” - a sudden burst of trouble across the network.
We’ve been working on improving this for about two years. We didn’t believe it could be truly fixed, but now we’re having trouble reproducing the behavior!
In this (long) article, I’m going to walk through the problem and the multi-year process of tackling it.
eBPF Maps and Locking
LibreQoS (via the lqos_sys system) goes out of its way to avoid locking on the hot packet path during normal operation.
In version 1.4, when a packet arrived:
- We “dissect” the packet - read through VLAN/PPPoE/etc. headers until we find an IP payload. We then determine the source and destination addresses, protocol (TCP/UDP/ICMP), and either port numbers (for TCP/UDP) or ICMP type/code.
- IP addresses are normalized into an IPv6-compatible format.
- We perform an LPM (Longest Prefix Match) lookup on the
xdp-cpumapmap to identify which circuit an IP address belongs to. - We redirect via a
cpumapto the appropriate CPU (allowingmqandhtbto use all your server cores). - A second
tcclassifier eBPF program fires and assigns the packet to the correct traffic-control lane.
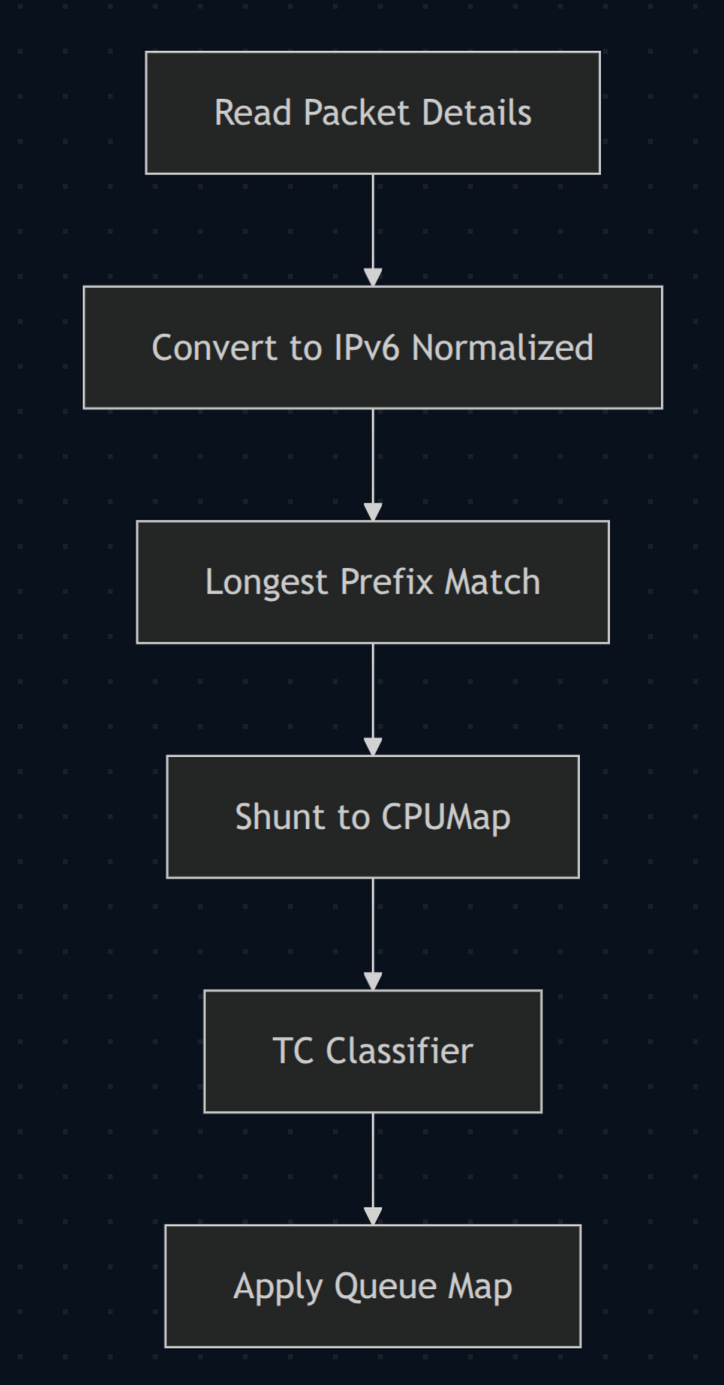
Reloading meant updating the xdp-cpumap map from user space. Those updates require write-side synchronization inside the kernel, and under heavy load that contention could become very noticeable. XDP/TC programs don’t have much budget per packet; once you get close to the line, even short stalls can show up as bursts of packet loss.
It’s worth noting that Linux’s RCU-based synchronization here is absolutely amazing, so this isn’t a grumble about Linux. It was just a bad update pattern on our side.
Introducing eBPF Iterators
In version 1.4, we realized we were doing something stupid. We were locking the entire xdp-cpumap map, deleting items
one by one and re-adding them on a reload. We switched to a “bulk delete” system and saw immediate improvement.
We also adopted the BPF iterator API, and traversing the data became much better behaved. Small ISPs rarely saw the problem, but large ISPs still struggled.
Adding Analysis Systems
As LibreQoS grew, Dave and I zeroed in on “all this shaping is great, but if we’re not measuring it - we can’t improve it” as a design philosophy. As a result, the eBPF grew too. We started tracking TCP round-trip time (RTT), assigning traffic to hosts in another eBPF map, adding a packet-capture path, and monitoring CAKE itself.
That was fantastic, and some of the most fun I’ve ever had developing software.
Unfortunately, it also came with a price: eBPF is hard to develop.
- The verifier forces you to prove every pointer access is in-bounds, and every loop is bounded.
- The stack is tiny (hundreds of bytes).
- General-purpose allocation is limited; most state lives in eBPF maps.
Those are great constraints, well within what Dave and I had dealt with in embedded and kernel code in the past. They also compound the locking problem - because now the program is doing more work per packet, so any extra contention during a reload makes it easier to fall behind and drop packets.
So we made LibreQoS better - and made the overall locking problem worse.
Flows
As version 1.5 came along, we decided that we also wanted to track “flows”. That is, data passing between two points on the Internet. It’s conceptually easy enough: you key by the usual 5-tuple (source IP, destination IP, protocol, source port, destination port) and accumulate flow data in a single location. It’s analytics gold, because now you can see which ASNs aren’t working properly (and fix routing) and you can see what is failing for users (you can watch them run a speed test in near real time).
And of course, it further complicated the locking problem!
So now our per-packet pipeline:
- Dissects the packet.
- Performs the LPM lookup.
- Calculates a flow hash.
- Updates per-host counters (these are per-CPU).
- Updates per-flow counters.
- Logs RTT and TCP retransmit detections (via a ring buffer).
- Shunts to
tc. - Repeats the dissection.
- Repeats the LPM lookup.
- Assigns to the correct
tcqueue - and off we go.
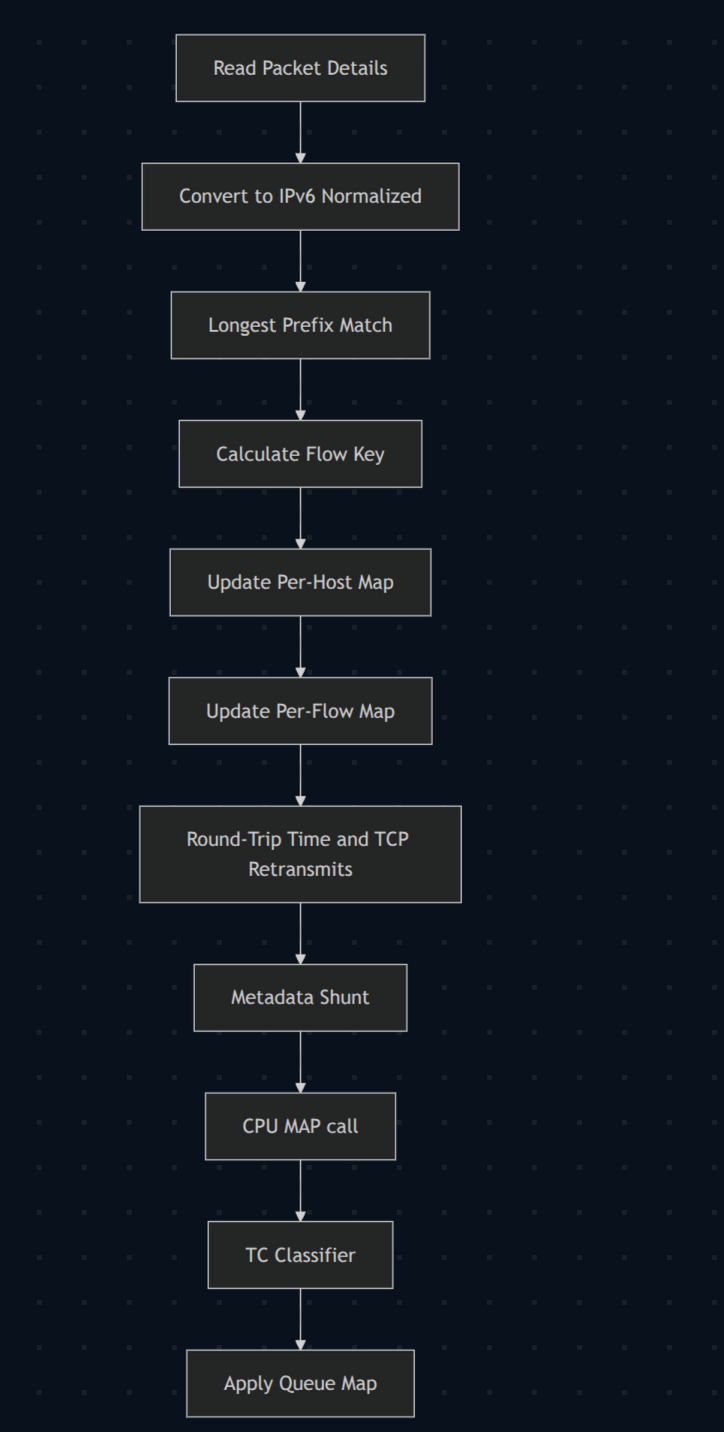
That’s really nice and powerful. We were pushing upwards of 40 Gbps on some boxes. It’s also rather flabby!
Enter The Hot Cache
Profiling showed that the LPM lookup in xdp-cpumap was a significant source of slowness in the per-packet path. So we added a second map: the “hot cache”. It’s a pretty nice cache; it supports both positive (“this IP maps to that circuit”) and negative (“this IP doesn’t exist, stop looking”) results in a fast hash map.
For each packet, we queried the hot cache first and only performed an LPM lookup if the cache missed. Boom: an instant 10–20% speedup in the LibreQoS packet-processing pipeline. We did happy dances.
And the reload stall was actually worse, because now we had to wipe the hot cache, too. Even with bulk functions, that turned out to be a slower operation.
Metadata Shunt
The Linux eBPF system gained “metadata” in general availability, as well as the ability to carry it between XDP and tc. That gives you a small chunk of space “in front of” the packet that you can use to pass data between an XDP program and a tc classifier. The verifier is strict here: if you don’t keep the pointers consistent, terrible things might happen. Fair enough; we can live with that.
So we implemented the “metadata shunt”. When a packet arrives, it is looked up with the hot cache/LPM, and the result is written to metadata for the next stage. That completely skips the need for a second map lookup. Another few percentage points of throughput improvement! But once again, the reload problem didn’t budge.
The Bakery
We’ve written about the bakery before. The short version is that we focused on reducing the number of changes we were making. It was a multi-stage process that eventually:
- Eliminated the need to completely wipe the
xdp-cpumapstate and rebuild it from scratch in 90% of reload cases. - Allowed for some changes (circuit additions and speed changes) to happen without a full reload.
We started to see some significant improvements in the reload story, but we weren’t there yet. Users who followed a “we rewrite the state of the network regularly” model still saw regular problems. For UISP, Splynx, and other integration users who tend to apply changes in batches, the improvements were significant - but the pause wasn’t gone.
Rearranging How We Classify
If you look at the previous diagrams, we are doing a lot of work per-packet. The “fun” part is that it is all good, necessary work. There aren’t any steps we can reasonably not perform.
And then I realized: we could do the same steps in a different order! So I rearranged the eBPF maps. The xdp-cpumap map changed to hold the circuit_hash and device_hash directly (to help the UI). The flow map was extended to hold the destination CPU and tc class.
And then we refactored the whole eBPF packet pipeline:
- Packet is dissected.
- Flow key is calculated (hash of source IP/destination IP/protocol/source port/destination port).
- A flow lookup is performed.
- If the flow does not exist: perform the hot cache + LPM lookup and populate the flow.
- If the flow does exist: skip the hot cache + LPM lookup altogether.
- Perform the same analytics.
- Metadata shunt to
tc-classify. cpumapassignment.- Assign to the correct queue.
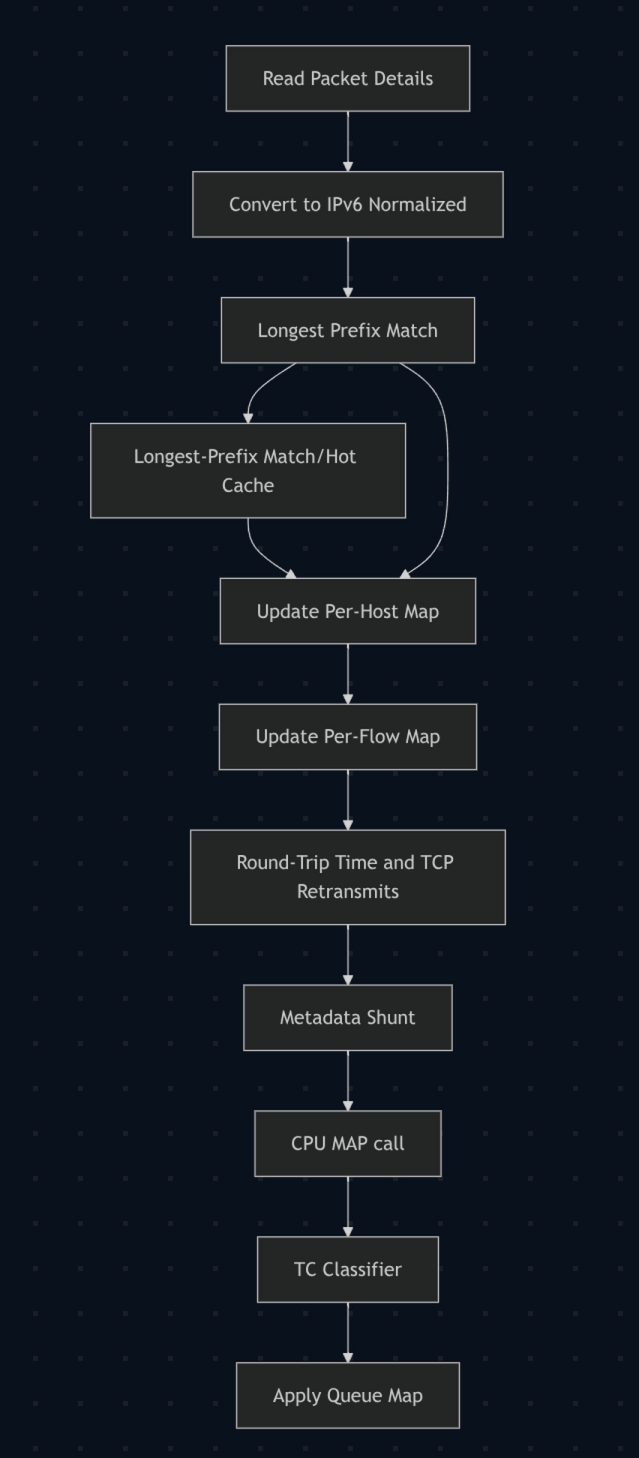
This is a HUGE win in terms of performance, because most flows are more than one packet long. In fact, the vast majority are at least 10 packets, with some going into the thousands of packets. So amortized across the whole system, we’re making an order of magnitude fewer loops.
And best of all: the maps that lock are being queried massively less often. That was an instant performance win, and it made the “wave of suck” pause much harder to trigger.
You might think that this is time for a happy dance and calling it done. But no - we came up with another trick!

Epochs
In this context, an “epoch” is really just a generation counter - a number that represents “which version of reality” a piece of cached data belongs to.
I was reading an article about the inner workings of memory garbage collectors (I needed help getting to sleep), and I stumbled upon a description of using epochs to avoid lock-heavy updates. You attach an epoch to data, bump the current epoch when reality changes, and treat older epochs as stale.
And I realized: we could do this for the hot cache and LPM data. So both were reworked, with an epoch bump replacing every wipe/overwrite cycle.
Each entry carries the epoch it was created under, and lookups treat an older epoch as a miss (so it gets refreshed naturally). Old entries stick around, but they get ignored and gradually replaced by real traffic (and, for LRU maps, evicted when the map fills). It led to some gnarly code and interesting debugging, but the short version: no more reload-time lock storms. We’ve hammered the system trying to recreate the problem, and it just keeps ticking along.

Wrap-Up
Writing this, I was overcome by how much I miss working with Dave on the low-level stuff. I miss you, mate. Rest in Peace.
Moving forward, this opens some exciting doors. We can change the tree around with very little penalty, so we suddenly have the ability to provide some long-requested features. These aren’t live yet, but they are coming:
- API calls for live circuit changes.
- Live adjustment to the network for performance reasons.
- The possibility of receiving RADIUS accounting packets to allow for dynamic queue creation for hotspots and live systems.
Exciting times! Thanks for sticking with me on a rather huge update. It’s exciting stuff. It’s also rather dry and technical, so I hope you’re still awake…
Acronyms
eBPF- extended Berkeley Packet Filter. Small programs that can run in the Linux kernel.QoE- Quality of Experience.XDP- eXpress Data Path. A high-performance packet-processing hook that runs very early in the Linux networking stack.RCU- Read-Copy-Update. A Linux synchronization mechanism commonly used for read-heavy data structures.RTT- Round-trip time.ASN- Autonomous System Number.RADIUS- Remote Authentication Dial-In User Service.tc- Linux Traffic Control. The Linux kernel portion that handles traffic shaping.CAKE- Common Applications Kept Enhanced. A Linuxqdiscused for queue management and shaping.htb- Hierarchical Token Bucket. The Linux kernel feature that allows you to define a tree of speed limits.mq- Multi Queue. Linux kernel feature that allows you to installmqat the top of HTB, and use multiple CPUs.LPM- Longest Prefix Match. Given an IP address (for example,192.168.1.5), returns the most specific matching prefix (for example,192.168.1.5/32beats192.168.1.0/24).